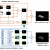
Figure 1: Pipeline of the proposed model. SM and Co-SM are abbreviations for saliency map and co-saliency map, respectively.
|
In this paper, a bottom-up and data-driven model is introduced to detect co-salient objects from an image pair. Inspired by the biologically-plausible across-scale architecture, we propose a multi-layer fusion algorithm to extract conspicuous parts from an input image. At each layer, two existing saliency models are first combined to obtain an initial saliency map, which simultaneously codes for the color names based surrounded cue and the background measure based boundary connectivity. Then a global color cue with respect to color names is invoked to refine and fuse single-layer saliency results. Finally, we exploit the color names based distance metric to measure the color consistency between a pair of saliency maps and remove those non-co-salient regions. The proposed model can generate both saliency and co-saliency maps. Experimental results show that our model performs favorably against 14 saliency models and 6 co-saliency models on the Image Pair data set.
-
Jing Lou, Fenglei Xu, Qingyuan Xia, Wankou Yang*, Mingwu Ren*, ŌĆ£Hierarchical Co-salient Object Detection via Color Names,ŌĆØ in Proceedings of the Asian Conference on Pattern Recognition (ACPR), pp. 718ŌĆō724, 2017. (Spotlight)
PDF Bib MATLAB Code Slides (in Chinese) Spotlight Slides Poster -
The developed MATLAB code of CNS [17] is available at ŌĆ£Exploiting Color Name Space for Salient Object DetectionŌĆØ.
-
We provide the saliency/co-saliency maps of the proposed HCN model on the Image Pair data set [13]. The zip files can be downloaded from GitHub below or Baidu Cloud. We also provide three evaluation measures including Precision-Recall curve, F-measure curve, and Precision-Recall bar in each zip file, please see the help text in the PlotPRF script. If you use any part of our saliency/co-saliency maps or evaluation measures, please cite our paper.
Dataset Images Results Reference Image Pair 105 image pairs (i.e., 210 images) ImagePair_HCNsImagePair_HCNco • H. Li and K. N. Ngan, “A Co-Saliency Model of Image Pairs,” IEEE Trans. Image Process., 20(12): 3365–3375, 2011. -
The proposed HCN model is also a salient object detection model, so we provide the improved MATLAB Code and single-image saliency maps on the following benchmark datasets. The zip files can be downloaded from GitHub below or Baidu Cloud. We also provide two evaluation measures including Precision-Recall and F-measure in each zip file, please see the help text in the PlotPRF script. If you use any part of our saliency maps or evaluation measures, please cite our paper.
Dataset Images Saliency Maps References ASD (MSRA1000
/MSRA1K)1000 ASD_HCNs • T. Liu, J. Sun, N.-N. Zheng, X. Tang, and H.-Y. Shum, ŌĆ£Learning to detect a salient object,ŌĆØ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2007, pp. 1–8.
• R. Achanta, S. Hemami, F. Estrada, and S. Süsstrunk, ŌĆ£Frequency-tuned salient region detection,ŌĆØ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2009, pp. 1597–1604.DUTOMRON 5166 DUTOMRON_HCNs • C. Yang, L. Zhang, H. Lu, X. Ruan, and M.-H. Yang, ŌĆ£Saliency detection via graph-based manifold ranking,ŌĆØ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2013, pp. 3166–3173. ECSSD 1000 ECSSD_HCNs • Q. Yan, L. Xu, J. Shi, and J. Jia, ŌĆ£Hierarchical saliency detection,ŌĆØ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2013, pp. 1155–1162.
• J. Shi, Q. Yan, L. Xu, and J. Jia, ŌĆ£Hierarchical image saliency detection on extended CSSD,ŌĆØ IEEE Trans. Pattern Anal. Mach. Intell., vol. 38, no. 4, pp. 717–729, 2016.ImgSal 235 ImgSal_HCNs • J. Li, M. D. Levine, X. An, and H. He, ŌĆ£Saliency Detection Based on Frequency and Spatial Domain Analysis,ŌĆØ in Proc. Br. Mach. Vis. Conf., 2011, pp. 86: 1–11.
• J. Li, M. D. Levine, X. An, X. Xu, and H. He, ŌĆ£Visual saliency based on scale-space analysis in the frequency domain,ŌĆØ IEEE Trans. Pattern Anal. Mach. Intell., vol. 35, no. 4, pp. 996–1010, 2013.JuddDB 900 JuddDB_HCNs • T. Judd, K. Ehinger, F. Durand, and A. Torralba, ŌĆ£Learning to predict where humans look,ŌĆØ in Proc. IEEE Int. Conf. Comput. Vis., 2009, pp. 2106–2113.
• A. Borji, ŌĆ£What is a salient object? A dataset and a baseline model for salient object detection,ŌĆØ IEEE Trans. Image Process., vol. 24, no. 2, pp. 742–756, 2015.MSRA10K 10000 MSRA10K_HCNs • T. Liu, J. Sun, N.-N. Zheng, X. Tang, and H.-Y. Shum, ŌĆ£Learning to detect a salient object,ŌĆØ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2007, pp. 1–8.
• R. Achanta, S. Hemami, F. Estrada, and S. Süsstrunk, ŌĆ£Frequency-tuned salient region detection,ŌĆØ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2009, pp. 1597–1604.
• M.-M. Cheng, N. J. Mitra, X. Huang, P. H. S. Torr, and S.-M. Hu, ŌĆ£Global contrast based salient region detection,ŌĆØ IEEE Trans. Pattern Anal. Mach. Intell., vol. 37, no. 3, pp. 569–582, 2015.SED2 100 SED2_HCNs • S. Alpert, M. Galum, R. Basri, and A. Brandt, ŌĆ£Image segmentation by probabilistic bottom-up aggregation and cue integration,ŌĆØ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2007, pp. 1–8.
• A. Borji, D. N. Sihite, and L. Itti, ŌĆ£Salient object detection: A benchmark,ŌĆØ in Proc. Eur. Conf. Comput. Vis., 2012, pp. 414–429.THUR15K 6232 THUR15K_HCNs • M.-M. Cheng, N. J. Mitra, X. Huang, and S.-M. Hu, ŌĆ£SalientShape: Group saliency in image collections,ŌĆØ Vis. Comput., vol. 30, no. 4, pp. 443–453, 2014.

Figure 6: Performance of the proposed model compared with 14 saliency models (top) and 6 co-saliency models (bottom) on the Image Pair data set. (a) Precision (y-axis) and recall (x-axis) curves. (b) F-measure (y-axis) curves, where the x-axis denotes the fixed threshold
![T_f \in [0,255]](https://s0.wp.com/latex.php?latex=T_f+%5Cin+%5B0%2C255%5D&bg=ffffff&fg=000&s=-2&c=20201002) . (c) Precision-recall bars, sorted in ascending order of the . (c) Precision-recall bars, sorted in ascending order of the 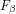 values obtained by adaptive thresholding. values obtained by adaptive thresholding. |

Figure 7: Visual comparison of co-saliency detection results. (a)-(b) Input images and ground truth masks [13]. Co-saliency maps produced using (c) the proposed model, (d) CoIRS [11], (e) CBCS [12], (f) IPCS [13], (g) CSHS [14], (h) SACS [15], and (i) IPTDIM [16], respectively.
|
The authors would like to thank Huan Wang, Andong Wang, Haiyang Zhang, and Wei Zhu for helpful discussions. They also thank Zun Li for providing some evaluation data. This work is supported by the National Natural Science Foundation of China (Nos. 61231014, 61403202, 61703209) and the China Postdoctoral Science Foundation (No. 2014M561654).