Figure 2 Framework of the proposed CNS model.
|
In this paper, we will investigate the contribution of color names for the task of salient object detection. An input image is first converted to color name space, which is consisted of 11 probabilistic channels. By exploiting a surroundedness cue, we obtain a saliency map through a linear combination of a set of sequential attention maps. To overcome the limitation of only using the surroundedness cue, two global cues with respect to color names are invoked to guide the computation of a weighted saliency map. Finally, we integrate the above two saliency maps into a unified framework to generate the final result. In addition, an improved post-processing procedure is introduced to effectively suppress image backgrounds while uniformly highlight salient objects. Experimental results show that the proposed model produces more accurate saliency maps and performs well against twenty-one saliency models in terms of three evaluation metrics on three public data sets.
-
Jing Lou*, Huan Wang, Longtao Chen, Fenglei Xu, Qingyuan Xia, Wei Zhu, Mingwu Ren*, ŌĆ£Exploiting Color Name Space for Salient Object Detection,ŌĆØ Multimedia Tools and Applications, vol. 79, no. 15, pp. 10873ŌĆō10897, 2020. doi:10.1007/s11042-019-07970-x
PDF Bib MATLAB Code -
We provide the saliency maps of the proposed CNS model on the following benchmark data sets. These saliency maps are generated by using MATLAB R2014b (version 8.4). The zip files can be downloaded from GitHub below or Baidu Cloud. We also provide two evaluation measures including Precision-Recall and F-measure in each zip file, please see the help text in the PlotPRF script. If you use any part of our saliency maps or evaluation measures, please cite our paper.
Data set Images Saliency Maps References ASD (MSRA1000
/MSRA1K)1000 ASD_CNS • T. Liu, J. Sun, N.-N. Zheng, X. Tang, and H.-Y. Shum, ŌĆ£Learning to detect a salient object,ŌĆØ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2007, pp. 1–8.
• R. Achanta, S. Hemami, F. Estrada, and S. Süsstrunk, ŌĆ£Frequency-tuned salient region detection,ŌĆØ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2009, pp. 1597–1604.DUTOMRON 5166 DUTOMRON_CNS • C. Yang, L. Zhang, H. Lu, X. Ruan, and M.-H. Yang, ŌĆ£Saliency detection via graph-based manifold ranking,ŌĆØ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2013, pp. 3166–3173. ECSSD 1000 ECSSD_CNS • Q. Yan, L. Xu, J. Shi, and J. Jia, ŌĆ£Hierarchical saliency detection,ŌĆØ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2013, pp. 1155–1162.
• J. Shi, Q. Yan, L. Xu, and J. Jia, ŌĆ£Hierarchical image saliency detection on extended CSSD,ŌĆØ IEEE Trans. Pattern Anal. Mach. Intell., vol. 38, no. 4, pp. 717–729, 2016.ImgSal 235 ImgSal_CNS • J. Li, M. D. Levine, X. An, and H. He, ŌĆ£Saliency Detection Based on Frequency and Spatial Domain Analysis,ŌĆØ in Proc. Br. Mach. Vis. Conf., 2011, pp. 86: 1–11.
• J. Li, M. D. Levine, X. An, X. Xu, and H. He, ŌĆ£Visual saliency based on scale-space analysis in the frequency domain,ŌĆØ IEEE Trans. Pattern Anal. Mach. Intell., vol. 35, no. 4, pp. 996–1010, 2013.JuddDB 900 JuddDB_CNS • T. Judd, K. Ehinger, F. Durand, and A. Torralba, ŌĆ£Learning to predict where humans look,ŌĆØ in Proc. IEEE Int. Conf. Comput. Vis., 2009, pp. 2106–2113.
• A. Borji, ŌĆ£What is a salient object? A dataset and a baseline model for salient object detection,ŌĆØ IEEE Trans. Image Process., vol. 24, no. 2, pp. 742–756, 2015.MSRA10K 10000 MSRA10K_CNS • T. Liu, J. Sun, N.-N. Zheng, X. Tang, and H.-Y. Shum, ŌĆ£Learning to detect a salient object,ŌĆØ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2007, pp. 1–8.
• R. Achanta, S. Hemami, F. Estrada, and S. Süsstrunk, ŌĆ£Frequency-tuned salient region detection,ŌĆØ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2009, pp. 1597–1604.
• M.-M. Cheng, N. J. Mitra, X. Huang, P. H. S. Torr, and S.-M. Hu, ŌĆ£Global contrast based salient region detection,ŌĆØ IEEE Trans. Pattern Anal. Mach. Intell., vol. 37, no. 3, pp. 569–582, 2015.SED2 100 SED2_CNS • S. Alpert, M. Galum, R. Basri, and A. Brandt, ŌĆ£Image segmentation by probabilistic bottom-up aggregation and cue integration,ŌĆØ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2007, pp. 1–8.
• A. Borji, D. N. Sihite, and L. Itti, ŌĆ£Salient object detection: A benchmark,ŌĆØ in Proc. Eur. Conf. Comput. Vis., 2012, pp. 414–429.THUR15K 6232 THUR15K_CNS • M.-M. Cheng, N. J. Mitra, X. Huang, and S.-M. Hu, ŌĆ£SalientShape: Group saliency in image collections,ŌĆØ Vis. Comput., vol. 30, no. 4, pp. 443–453, 2014.

Figure 9 Performance of the proposed model compared with twenty-one saliency models on ASD [24,2], ECSSD [48,40], and ImgSal [22,23], respectively. (a) Precision-Recall curves. (b)
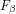 -measure curves. (c) Precision-Recall bars. -measure curves. (c) Precision-Recall bars. |

Figure 10 Visual comparison of salient object detection results. Top three rows, middle three rows, and bottom three rows are from ASD [24,2], ECSSD [48,40], and ImgSal [22,23], respectively. (a) Input images, and (b) ground truth masks. Saliency maps produced by using (c) the proposed CNS model, (d) RPC [25], (e) BMS [52], (f) FES [42], (g) GC [8], (h) HFT [23], (i) PCA [28], (j) RC [9], and (k) TLLT [13].
|
J. Lou is supported by the Changzhou Key Laboratory of Industrial Internet and Data Intelligence (No. CM20183002) and the QingLan Project of Jiangsu Province (2018). The work of L. Chen, F. Xu, W. Zhu, and M. Ren is supported by the National Natural Science Foundation of China (Nos. 61231014 and 61727802). H. Wang is supported by the National Defense Pre-research Foundation of China (No. 9140A01060115BQ02002) and the National Natural Science Foundation of China (No. 61703209). Q. Xia is supported by the National Natural Science Foundation of China (No. 61403202) and the China Postdoctoral Science Foundation (No. 2014M561654). The authors thank Andong Wang and Haiyang Zhang for helpful discussions regarding this manuscript.